1. Introduction
更新: 3/1/2026 字数: 0 字 时长: 0 分钟
路由 (routing):控制平面功能,决定数据包从源到目标的整体路径。
构建网络控制平面的两种方法
每个路由器独立控制 (Per-router control) (传统方式)
- 路由算法的组件运行在每一台路由器上。
- 各个路由器通过相互通信来共同计算和维护路由信息。
逻辑上集中的控制 (Logically centralized control) (软件定义网络SDN)
- 一个远程的控制器(或一组控制器)负责计算转发表。
- 控制器将计算好的转发表下发并安装到各个路由器中。
- 路由器本身主要负责数据平面的转发,而“大脑”(控制逻辑)则集中在控制器。
2. 路由协议
更新: 3/1/2026 字数: 0 字 时长: 0 分钟
2.1 路由协议的目标
- 目标:通过路由器网络,为数据包从发送主机到接收主机确定“好的”路径(或路由)。
- 路径 (Path):数据包从源主机到目标主机所经过的一系列路由器。
- “好”的定义:通常指“成本最低”、“速度最快”或“最不拥塞”的路径。
路由选择被认为是网络领域的“十大挑战”之一。
2.2 路由算法分类 (Routing algorithm classification)
路由算法可以根据几个标准进行分类,其中一个关键的分类标准是信息的全局性或分散性:
全局信息 (Global information) - 链路状态算法 (Link State algorithms)
- 在这类算法中,所有路由器都拥有整个网络的完整拓扑信息和所有链路的成本信息。
- 每个路由器都能“看清”整个网络的全貌。
- 这类算法也被称为“链路状态 (LS)”算法。
分散信息 (Decentralized information) - 距离向量算法 (Distance Vector algorithms)
- 在这类算法中,路由器以迭代的方式进行计算,并与其邻居交换路由信息。
- 最初,每个路由器只知道与其直接相连的链路的成本。它们不了解整个网络的拓扑。
- 路由器通过与邻居不断地交换信息,逐步计算出到达其他节点的路径和成本。
- 这类算法也被称为“距离向量 (DV)”算法。
另一个分类维度是路由变化的快慢:
- 静态路由 (Static):路由变化非常缓慢,通常是网络管理员手动配置或不经常更新。
- 动态路由 (Dynamic):路由会更频繁地改变,可以周期性地更新,或者在链路成本发生变化时响应式地更新。现代路由协议通常是动态的。
2.3 链路状态路由算法:Dijkstra算法 (Link-State Routing Algorithm: Dijkstra’s Algorithm)
中心化算法思想:虽然路由计算是分布在每个路由器上独立进行的,但Dijkstra算法本身是一个“中心化”的算法,因为它要求执行算法的那个节点(路由器)必须知道网络中所有节点和所有链路的成本。
信息获取方式:这个全局信息是通过 “链路状态广播 (link state broadcast)” 来实现的,即每个路由器都会向网络中的所有其他路由器通告它自己直连链路的状态和成本。最终,所有节点都会拥有相同的、完整的网络拓扑信息。
计算目标:Dijkstra算法计算从一个源节点(执行该算法的路由器)到网络中所有其他节点的最低成本路径 (least cost paths)。
结果:计算完成后,可以得到该源节点的转发表 (forwarding table)。
迭代过程:算法是迭代进行的。在第k次迭代之后,就能知道到达k个目标节点的最低成本路径。
2.3.1 符号约定 (Notation)
为了理解算法步骤,我们先熟悉一下PPT中使用的符号:
c(x,y): 节点x到节点y的直接相连链路的成本。如果x和y不直接相邻,则成本为∞。 D(v): 从源节点到目标节点v的当前已知的最低成本路径的估计值。 p(v): 从源节点到节点v的最低成本路径上,v的前一个节点 (predecessor node)。 N': 一个节点集合,其中包含所有已经确定了其最低成本路径的节点。
2.3.2 Dijkstra算法步骤
初始化 (Initialization):
- N' 集合初始只包含源节点 u (我们从节点u开始计算到所有其他节点的路径)。
- 对于所有其他节点 v:
- 如果 v 与 u 直接相邻,则 D(v) = c(u,v) (初始时,到邻居的成本就是直接链路成本,但这不一定是最终的最低成本)。
- 如果 v 与 u 不直接相邻,则 D(v) = ∞。
循环 (Loop):重复以下步骤,直到所有节点都加入到 N' 集合中。
- 找到不在 N' 中的节点 w,使得 D(w) 是最小的。
- 将 w 加入到 N' 集合中。
- 更新所有与 w 相邻且不在 N' 中的节点 v 的 D(v) 值: D(v) = min( D(v), D(w) + c(w,v) )。
- 这步的含义是:到达节点 v 的新的最低成本路径,要么是之前已知的到达 v 的路径成本 (D(v)),要么是通过新加入到 N' 中的节点 w 再加上从 w 到 v 的直接链路成本 (D(w) + c(w,v)),取两者中较小的一个。如果通过 w 的路径成本更低,那么 p(v) 就会被更新为 w。
Dijkstra算法通过这种迭代的方式,一步步地扩展已知最低成本路径的节点集合,直到覆盖网络中的所有节点。
2.3.3 Dijkstra算法的复杂度
- 算法复杂度:对于有n个节点的网络。
- 朴素实现的比较次数是 n(n+1)/2,所以复杂度是 O(n²)。
- 使用更高效的实现(例如使用优先队列/堆)可以将复杂度优化到 O(nlogn) 或 O(E + nlogn) 其中E是链路数。
- 消息复杂度 (链路状态广播):
- 每个路由器需要向其他n-1个路由器广播其链路状态信息。
- 高效的广播算法可以使一个广播消息经过 O(n) 条链路到达所有节点。
- 由于有n个节点进行广播,总的消息复杂度大约是 O(n²)。
LimBoo注:此处复杂度的计算忽略了更新所有与节点相邻且不在 N' 中的节点 v 的 D(v) 值的复杂度,因为这一步相对耗时低。
2.3.4 Dijkstra算法:可能的振荡 (Dijkstra’s algorithm: oscillations possible)
问题背景:当链路的成本 (link costs) 取决于该链路上承载的流量时(例如,流量越大,成本越高,代表越拥堵),就可能发生路由振荡的现象。
过程:
- 初始状态:假设网络中的路由器根据当前的链路成本(可能与流量相关)计算出了最优路径。
- 流量迁移:所有路由器都将它们的流量导向这些“最优”路径。
- 成本变化:由于大量流量集中到了这些路径上,导致这些路径上的链路成本(因为拥堵)急剧上升,而之前未被选中的路径因为流量减少,成本反而下降。
- 重新计算路由:路由器检测到链路成本的变化,于是重新运行路由算法。它们现在可能会发现,之前那些未被选中的、成本较低的路径变成了新的“最优”路径。
- 再次流量迁移:于是,流量又会从之前拥堵的路径迁移到这些新选出的路径上。
- 再次成本变化:这又会导致新的路径变得拥堵、成本上升,而旧的路径成本下降。
- 这个过程可能会循环往复,导致路由在几条路径之间来回摆动,这就是路由振荡。
如何避免或减轻路由振荡?
- 一种方法是让链路成本不完全依赖于瞬时流量,或者引入一些阻尼机制,使得路由不会对链路成本的微小或短暂变化做出过于敏感的反应。
- 另一种方法是确保不是所有路由器都同时更新它们的路由表。
2.4 距离向量路由算法 (Distance Vector Algorithm)
基于Bellman-Ford方程:距离向量算法是基于著名的Bellman-Ford(BF)方程(一种动态规划方法)。
2.4.1 基本概念:
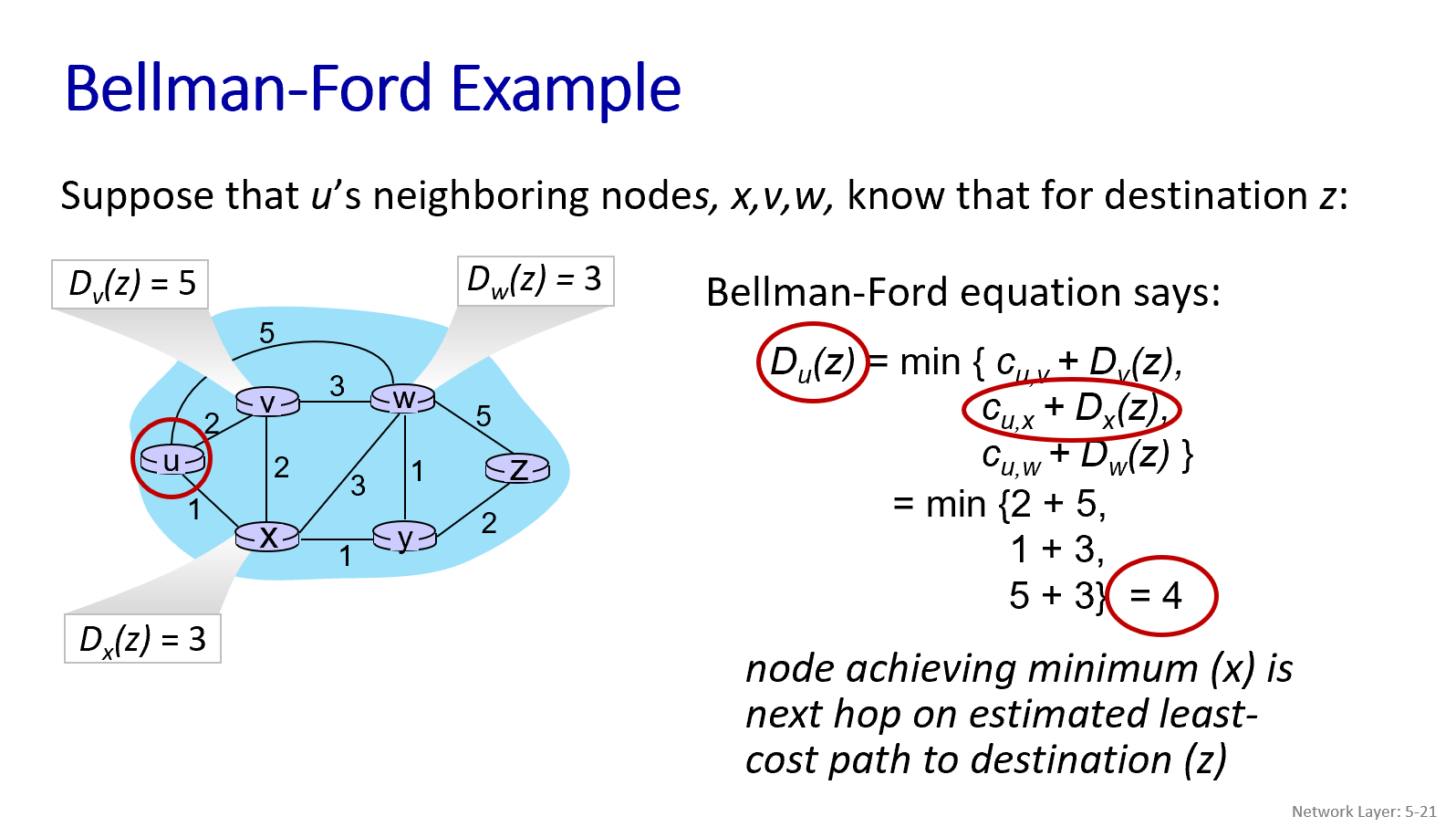
- Dx(y):表示从节点x到节点y的最低成本路径的成本估计值。
- Bellman-Ford方程:Dx(y) = min_v { c(x,v) + Dv(y) }。
- 这个公式的含义是:从节点x到节点y的最低成本,等于“从x到其某个邻居v的直接链路成本 c(x,v)” 加上 “从那个邻居v到最终目的地y的最低成本 Dv(y)” 之和的最小值。
- 这个 min_v 操作是在x的所有邻居v中进行的。
2.4.2 距离向量算法的运作方式
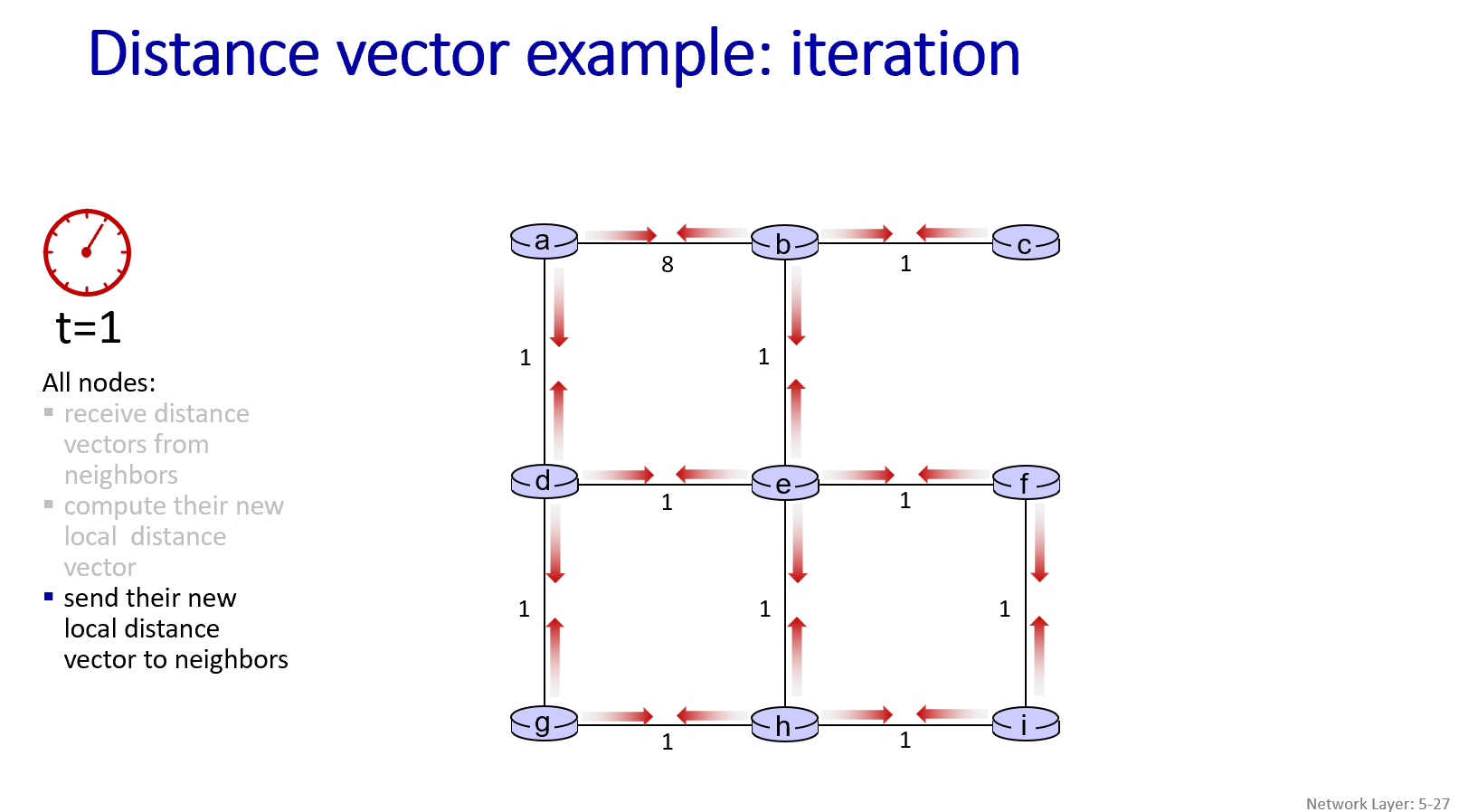
核心思想:每个节点维护一个距离向量 (Distance Vector - DV),这个向量包含了它自己到网络中所有其他目的地的当前最低成本估计。
信息交换:每个节点会周期性地或者在自身DV发生变化时,将其距离向量发送给它的所有直接邻居。
更新自身DV:当一个节点x从其任何一个邻居(比如v)那里收到一个新的距离向量估计时,它会使用Bellman-Ford方程来更新自己的距离向量:对于网络中的每一个目的地y,Dx(y) ← min_v{c(x,v) + Dv(y)}。
收敛性:在一些“次要的、自然的条件”下,各个节点对自己到其他节点的成本估计 Dx(y) 最终会收敛到实际的最低成本 dx(y)。
2.4.3 算法特点:
迭代的、异步的 (iterative, asynchronous):每个节点的本地迭代是由本地链路成本变化或收到邻居的DV更新消息触发的。
分布式的、自停止的 (distributed, self-stopping):每个节点只在它自己的DV发生变化时才通知其邻居;邻居也只有在自己的DV因此发生变化时才进一步通知它们的邻居。如果没有收到通知,节点不采取任何行动。
2.4.4 距离向量算法示例与信息传播
2.4.5 距离向量算法:链路成本变化与问题 (Distance Vector: Link Cost Changes & Problems)
- “好消息传播快” (Good news travels fast - PPT 5-38页)
- 当一条链路的成本减少时,这个好消息会相对较快地在网络中传播开来。
- 例子:
- 假设最初链路 y-x 的成本是4。节点y到x的最低成本是4 (Dy(x)=4),节点z到x的最低成本可能是通过y,即 Dz(x) = c(z,y) + Dy(x) = 1 + 4 = 5。
- t0: 节点y检测到它到x的链路成本从4变为1。y更新其Dy(x)为1,并通知其邻居(包括z)。
- t1: 节点z收到来自y的更新。z重新计算它到x的最低成本:Dz(x) = min { c(z,y) + Dy(x) } = min { 1 + 1 } = 2。由于z的DV发生了变化,z会通知它的邻居(比如y)。
- t2: 节点y收到来自z的更新。y重新计算它到x的最低成本(虽然它直接到x的成本是1,但它仍会基于邻居信息计算)。由于它到x的最低成本仍然是1(直接路径),它的距离向量可能不会改变,因此y可能不会再向z发送消息。
- 这个过程显示,当出现更优路径时,节点会迅速采纳并传播这个信息。
- “坏消息传播慢” - 无穷计数问题 (Bad news travels slow - Count-to-Infinity problem)
- 当一条链路的成本增加时,问题就可能出现,这就是经典的“无穷计数 (count-to-infinity)”问题。
- 例子:
- 假设最初链路 y-x 的成本是4,z-y 的成本是1。Dy(x)=4。z通过y到达x的成本是 Dz(x) = c(z,y) + Dy(x) = 1+4 = 5。
- 现在,链路 y-x 的成本突然从4急剧增加到60。
- y的困境:y检测到它直接到x的成本变成了60。但是,y之前从z那里听说,z可以以成本5到达x(这是基于旧信息,z以为y到x还是4)。所以,y可能会错误地认为:“虽然我直接到x要60,但我可以通过z到达x,成本是 c(y,z) + Dz(x)_{old} = 1 + 5 = 6。” 于是y更新 Dy(x)为6,下一跳指向z,并通知z。
- z的困境:z收到y的更新,说y到x的成本是6。z重新计算它到x的成本:“我可以通过y到达x,成本是 c(z,y) + Dy(x)_{new} = 1 + 6 = 7。” 于是z更新 Dz(x)为7,下一跳指向y,并通知y。
- 循环往复:y收到z的更新(Dz(x)=7),又以为可以通过z以成本 1+7=8 到达x。z收到y的更新(Dy(x)=8),又以为可以通过y以成本 1+8=9 到达x...
- 这个过程中,y和z之间形成了路由环路(y指向z,z指向y),并且它们对x的成本估计会一直缓慢地增加(6,7,8,9...),直到最终达到或超过某个阈值(比如实际的60)。这个缓慢增加的过程就是“无穷计数”。
- “see text for solutions”可作为一个解决方案,此处不详细展开。
“无穷计数”问题是距离向量算法的一个主要缺点,它会导致在网络拓扑或链路成本向坏的方向变化时,路由信息收敛非常缓慢,并且可能在收敛过程中产生临时的路由环路。
2.5 路由协议的比较
消息复杂度 (Message complexity):
- LS (链路状态):在有n个节点,E条链路的网络中,每个节点广播其链路状态。如果使用高效的广播,总的消息数量级是O(nE)或者说每个节点发送O(E)信息给所有其他节点,整体消息交换量较大。PPT中给出的是n个路由器,O(n²)条消息被发送。 (注:更精确的分析是,每个节点发送其链路状态,如果洪泛法,一条消息会遍历很多链路,总共O(nE)条消息的传输。如果指独立消息数量是n条,每条广播,那么理解为O(n²)次广播事件或链路传输也可以。)
- DV (距离向量):只在相邻节点之间交换距离向量信息。消息数量较少,但收敛时间会变化。
收敛速度 (Speed of convergence):
- LS:算法本身的计算复杂度是O(n²)(朴素实现)或O(nlogn) / O(E logn)(高效实现)。加上链路状态广播的时间,一旦所有信息收集完毕,计算是相对较快的。但是,如前所述,可能会有振荡问题。
- DV:收敛时间因网络拓扑和链路成本变化而异。可能会遇到路由环路和无穷计数问题,导致收敛缓慢。
健壮性 (Robustness):如果路由器发生故障或被会怎样?
- LS: 节点可能通告不正确的链路成本。 但是,由于每个路由器都是基于收到的完整拓扑信息独立计算自己的转发表,所以一个节点的计算错误通常不会直接影响其他节点的转发表计算(除非它广播了错误的链路状态信息,这会影响所有节点的计算基础)。
- DV: 一个DV路由器可能向其邻居通告不正确的路径成本(例如,声称自己有到达所有目的地的极低成本路径,可能导致“黑洞”路由,即数据包被吸引过去然后丢失)。 由于每个路由器的转发表计算依赖于其邻居的转发表(距离向量),错误信息很容易在网络中传播开来。
简单总结:
信息范围:LS是全局信息,DV是局部信息。 消息交换:LS广播给所有节点,DV只给邻居。 收敛性:LS在信息完整后计算较快但可能振荡;DV收敛慢,且有无穷计数和路由环路风险。 对错误信息的敏感度:DV中错误信息更容易传播。